
I am Jiayi Chen, a graduate in Automation from Tongji University (Class of 2019). Currently, I am pursuing my Master’s in Computer Science and Technology at Harbin Institute of Technology (HIT). Meanwhile, I serve as a Research Assistant at the IRPN Lab, Systems Hub, Hong Kong University of Science and Technology (Guangzhou), where my research focuses on Embodied Intelligence.
🔥 Project
-
Our GitHub repository(Embodied-AI-Paper-TopConf ), which collects academic papers in the field of embodied intelligence, has garnered over 300 stars.
-
Our open-source project LLaVA-VLA, a Vision-Language-Action model built upon the popular open-source VLM LLaVA, has received over 70 stars.
📝 Publications
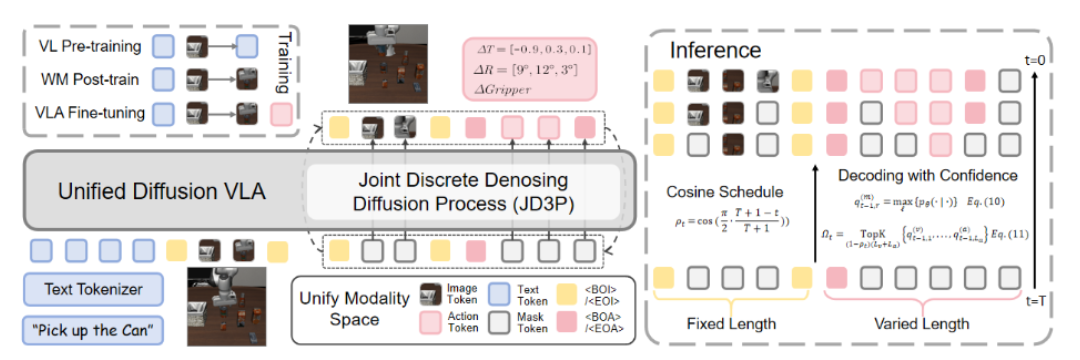
Unified Diffusion VLA: Vision-Language-Action Model via Joint Discrete Denoising Diffusion Process
Jiayi Chen, Wenxuan Song, Pengxiang Ding, Ziyang Zhou, Han Zhao, Feilong Tang, Donglin Wang, Haoang Li
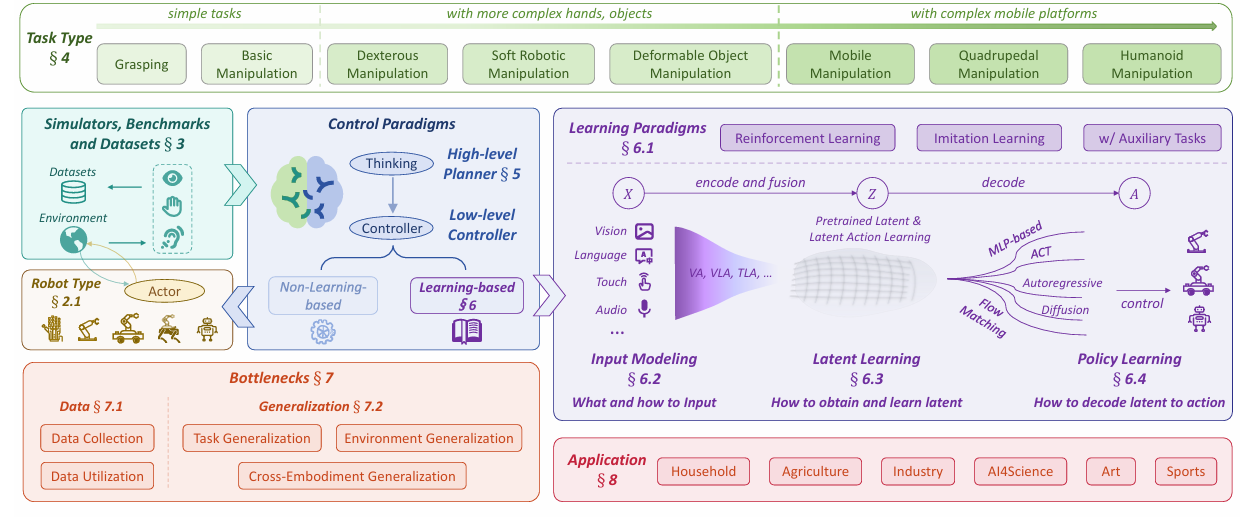
Towards a Unified Understanding of Robot Manipulation: A Comprehensive Survey
Shuanghao Bai, Wenxuan Song, Jiayi Chen, Yuheng Ji, Zhide Zhong, Jin Yang, Han Zhao, Wanqi Zhou, Wei Zhao, Zhe Li, Pengxiang Ding, Cheng Chi, Haoang Li, Chang Xu, Xiaolong Zheng, Donglin Wang, Shanghang Zhang, Badong Chen
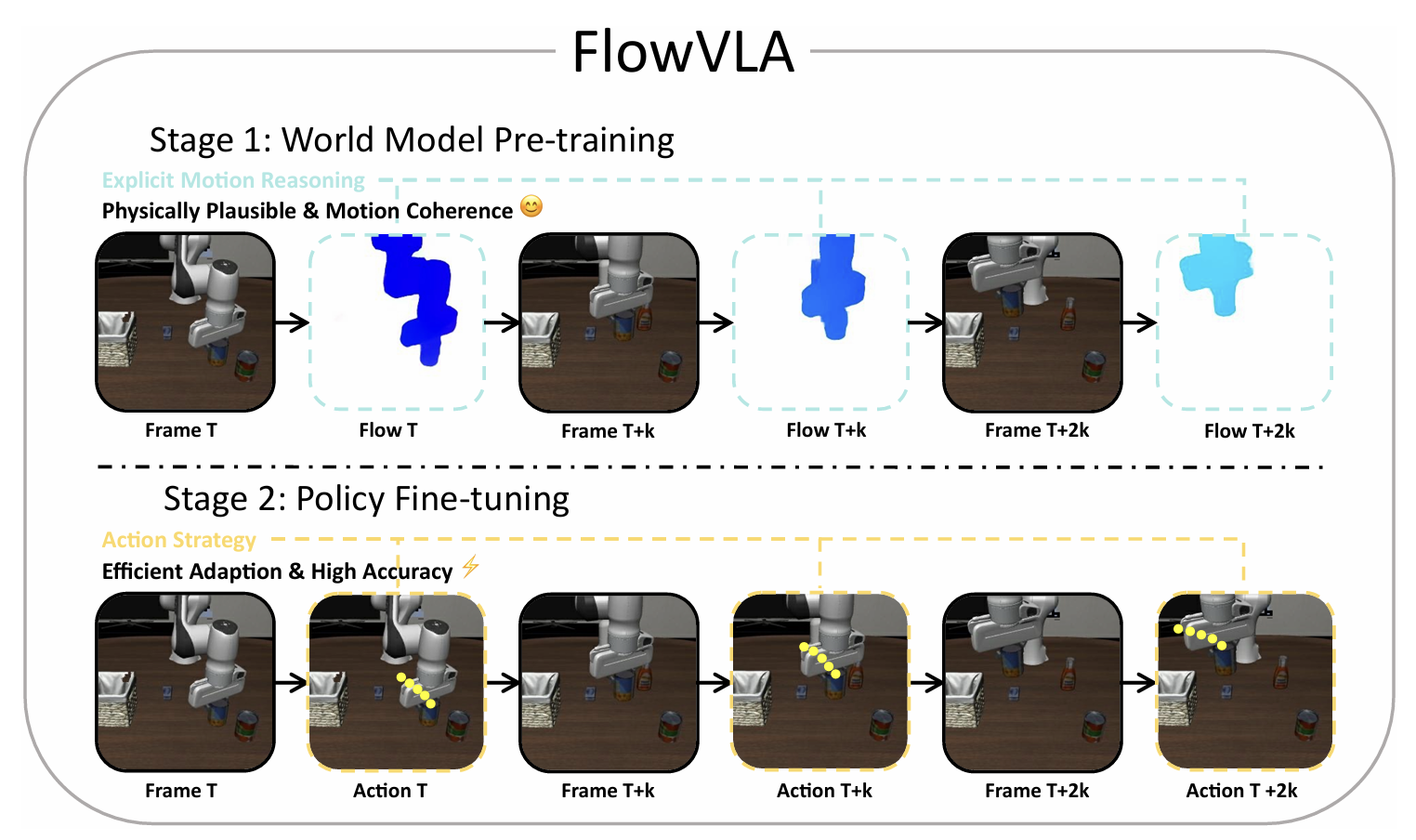
FlowVLA: Thinking in Motion with a Visual Chain of Thought
Zhide Zhong, Haodong Yan, Junfeng Li, Xiangchen Liu, Xin Gong, Wenxuan Song, Jiayi Chen, Haoang Li
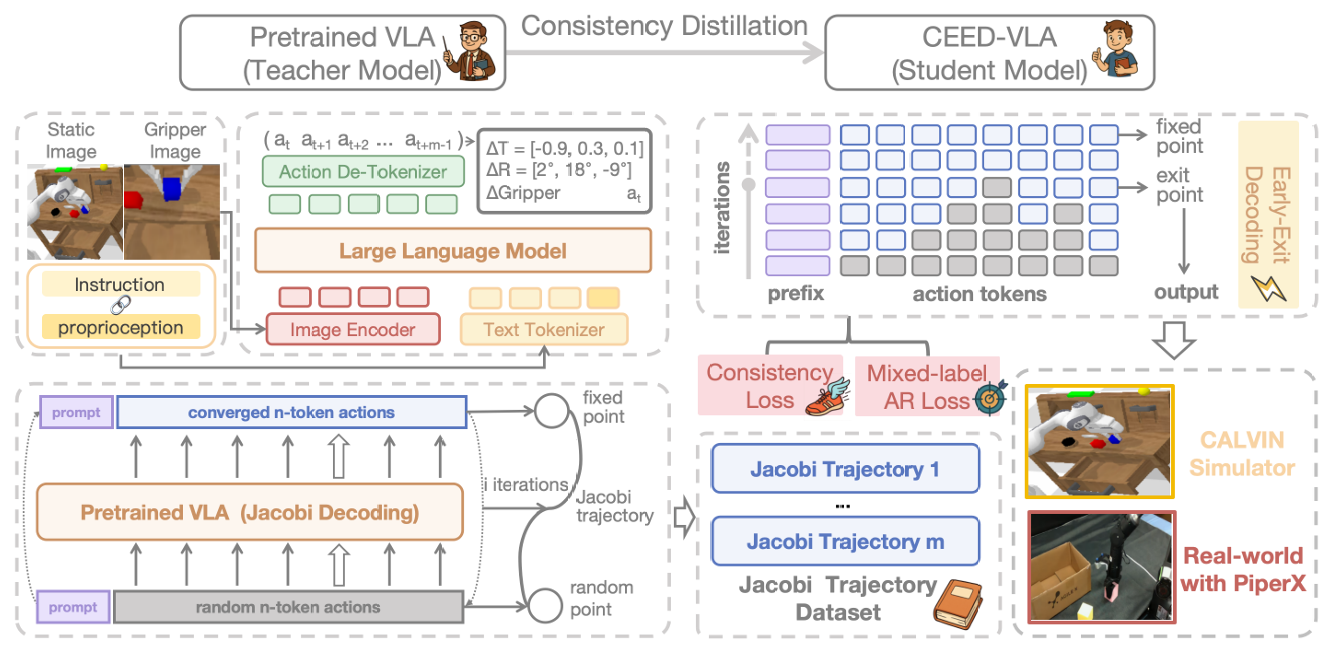
CEED-VLA: Consistency Vision-Language-Action Model with Early-Exit Decoding
Wenxuan Song¹*, Jiayi Chen¹*, Pengxiang Ding²˒³†, Yuxin Huang¹, Han Zhao²˒³, Donglin Wang², Haoang Li¹‡
¹ IRPN Lab, HKUST(GZ) ² MiLab, Westlake University ³ Zhejiang University
- Wepropose CEED-VLA, a universal acceleration method for significant inference speedup while maintaining manipulation performance.
- We conduct a consistency distillation process to unlock the model’s capabilities of fast inference.
- We identify the inefficient iteration as the bottleneck of Jacobi decoding’s speedup and propose the early-exit decoding to solve it.
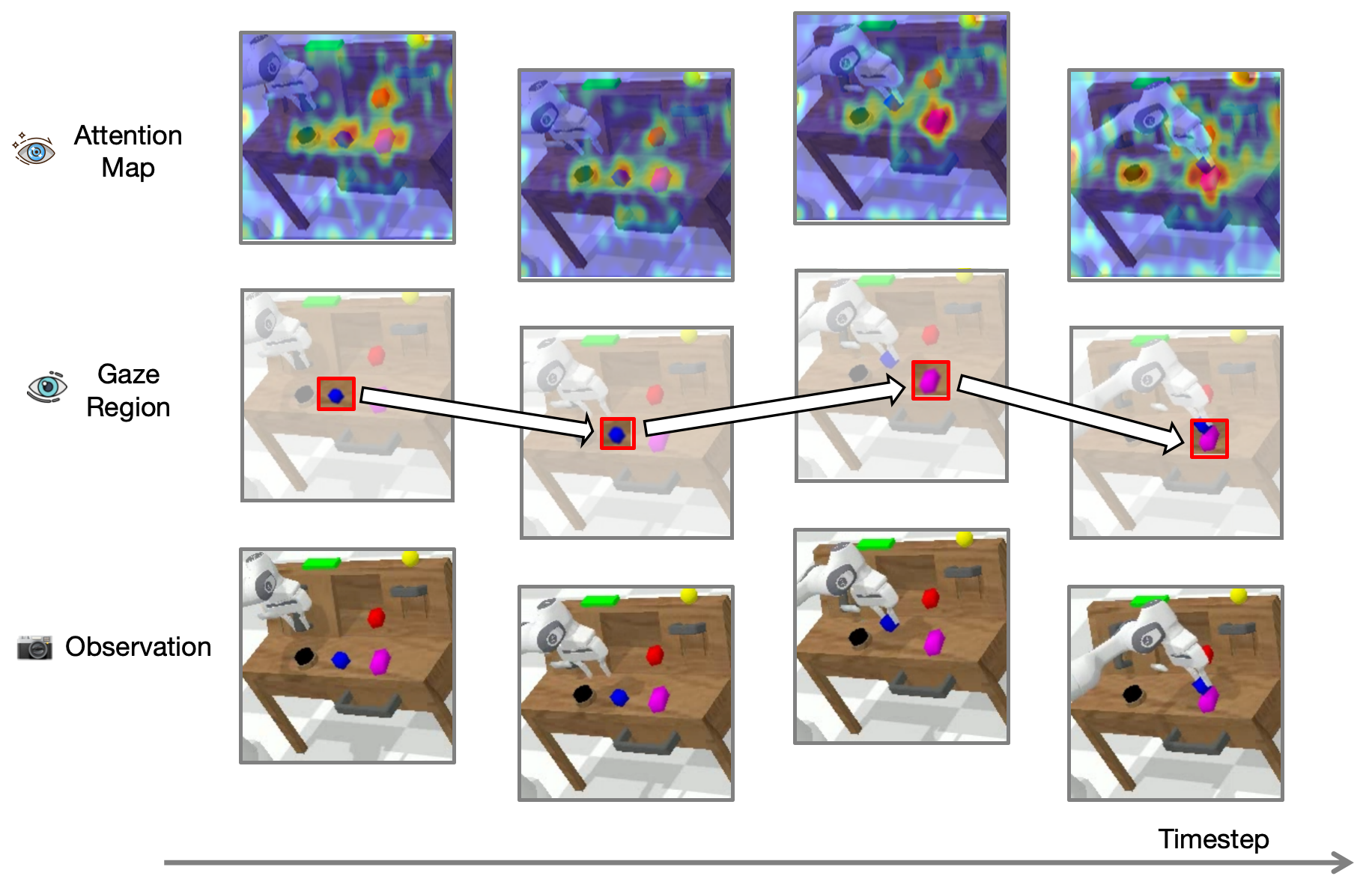
Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, Haoang Li
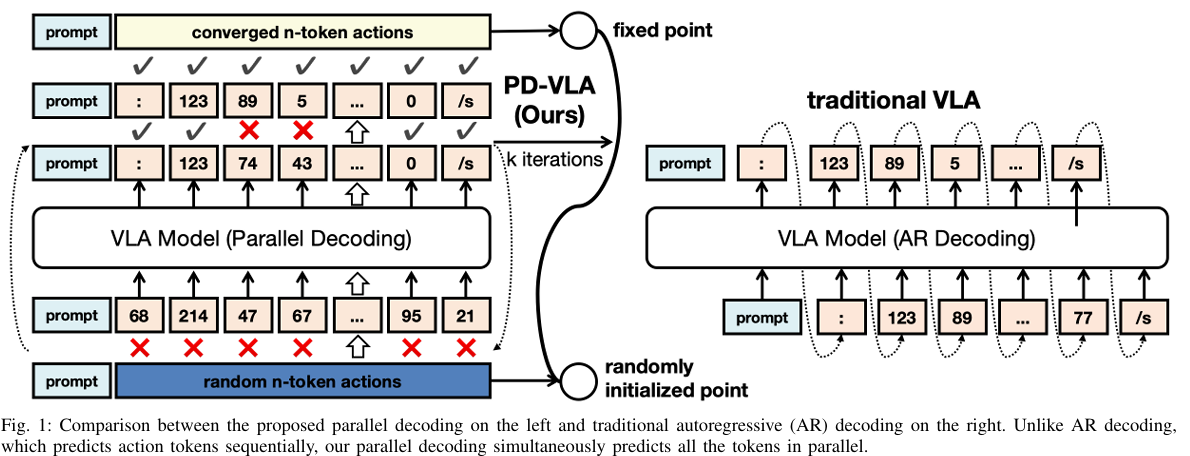
Accelerating Vision-Language-Action Model Integrated with Action Chunking via Parallel Decoding
Wenxuan Song¹*, Jiayi Chen¹*, Pengxiang Ding²˒³, Han Zhao²˒³, Wei Zhao²,Zhide Zhong¹, Zongyuan Ge⁴, Jun Ma¹, Haoang Li¹‡
¹ IRPN Lab, HKUST(GZ) ² MiLab, Westlake University ³ Zhejiang University ⁴ Monash University
We propose parallel decoding framework for VLA models integrated with action chunking.
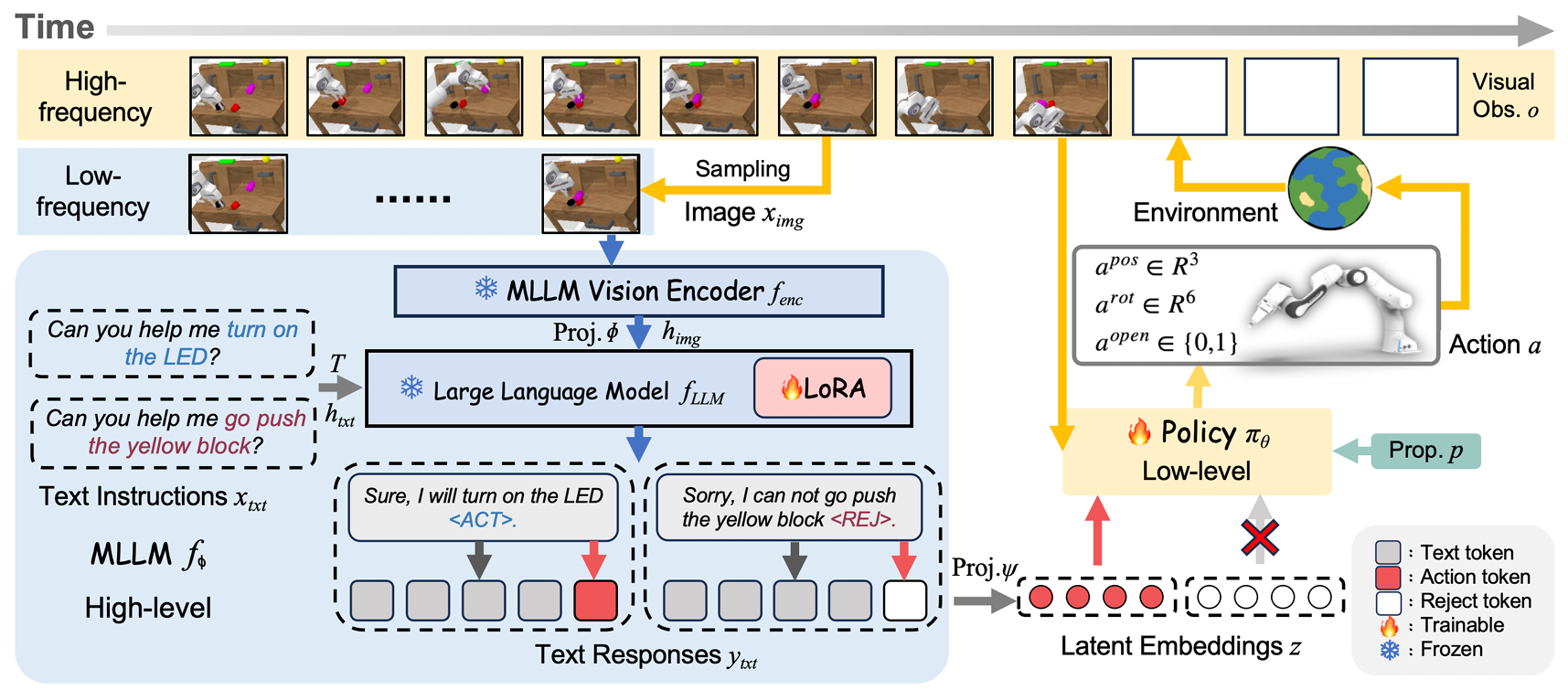
RationalVLA: A Rational Vision-Language-Action Model with Dual System
Wenxuan Song, Jiayi Chen, Wenxue Li, Xu He, Han Zhao, Can Cui, Pengxiang Ding, Shiyan Su, Feilong Tang,Donglin Wang, Xuelian Cheng, Zongyuan Ge, Xinhu Zheng, Zhe Liu, Hesheng Wang, Haoang Li
- We introduce a new benchmark, the Rational Manipula-tion (RAMA) with defective instructions in 6 dimensions.
- We propose Rational Vision-Language-Action model (RationalVLA). It is a dual system for the robotic armto perceive the environment, handle unseen and defective instructions effectively, and demonstrate performant manipulation capabilities.
📖 Educations
- 2023.06 - 2025.06 (now), Pursuing a Master’s degree in Computer Science and Technology at Harbin Institute of Technology.
- 2019.09 - 2023.06, Studied Automation at Tongji University and obtained a Bachelor’s degree in Engineering.
💻 Internships
- 2024.2 - 2024.06, IO Intelligence, China.